GitHub Spec Kit
GitHub Spec Kit was released in only the past few weeks. I have been experimenting with using it on my projects. As well as trying to stay across the changes and sentiments by consuming a lot of media, tutorials, and reading through the repo discussions & issues. As it is still early days and everyone is learning, I wanted to write up and share the current state of where the project is at, and how we’re all learning to use it.
GitHub Spec Kit overview
Spec Kit is an open‑source toolkit for spec‑driven development. Instead of vibe‑coding toward a moving target, you capture intent in a short spec, clarify what’s fuzzy, plan the how, slice it into tasks, and then let your coding agent implement inside clear guardrails.
Spec‑Driven Development (SDD) puts intent before implementation. You write the what/why as a tech‑agnostic spec; the how lives in a separate plan. The spec becomes the shared source of truth for humans and agents. When something doesn’t make sense you fix the spec first, not the code.
I’ve been using coding agents, and they are great for quickly experimenting and iterating. But once you get to larger more complex changes I was getting frustrated at the Agent changing unrelated things. I was spending more time correcting the agent than progressing. So far I am enjoying Spec Kit’s hierarchical structured way of directing the Agent.
Is it too heavy?
This is the most common question I am asked. For simple demos and test apps it can feel like a lot of overhead. There is a hierarchy of documents, and it does take some time to set up the initial constitution and first spec.
But once you’re working on larger features, or have constraints you need to uphold (security, architectural patterns, compliance) this structure looks to pay for itself quickly. Where I think it really earns its keep is in larger messy, real‑world projects.
Main use cases for Spec Kit
- Greenfield
- Where I expect most will start playing.
- Allows you to get the guardrails and vocabulary baked in early, getting consistent outcomes from the start.
- Existing systems - Adding new features
- In my opinion this is the best place for people to start playing with it on real projects.
- Planning inside constraints of a large codebase without breaking patterns.
- Legacy modernisation
- (In theory) Modernise a legacy system to a current tech stack and code base.
- Use an agent to capture business intent from an existing system, capture it in the specs. Rebuild from those specs with a fresh architecture plan.
- However I think the tooling still needs to mature before this becomes practical.
Getting set up
- Install instructions on https://github.com/github/spec-kit
- Installation CLI allows you to select your coding Agent (Copilot, Claude, Cursor, etc).
- Then it pulls down the Agent‑specific prompts, scripts, and markdown templates into
.github/promptsand.specify. - From there you can start using the
/slashcommands inside your chosen Agent.
The core flow
The flow keeps the what and why separate from the how. You set project rules, write the spec, answer clarifying questions, create a plan, turn it into small tasks, run a consistency check, then let the agent implement with review at each step.
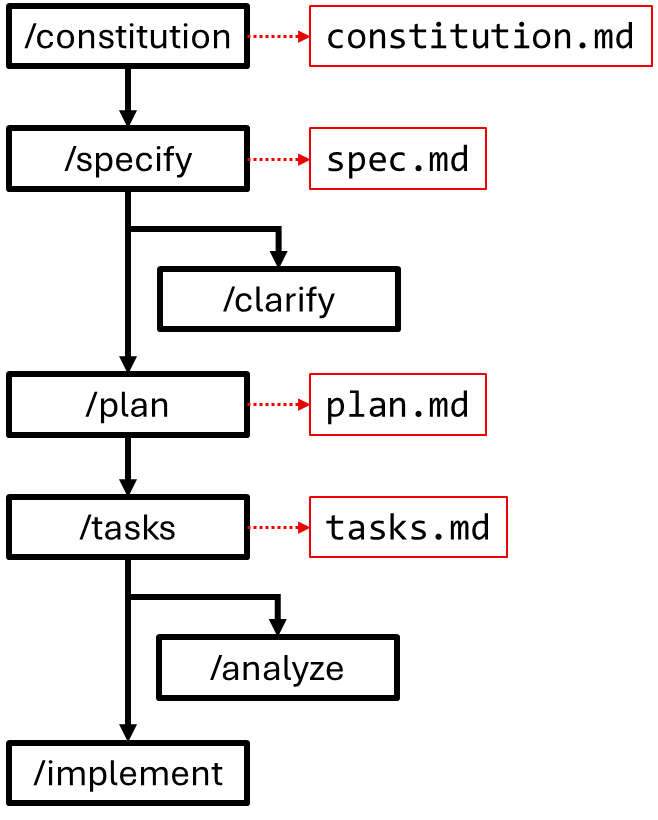
/constitution
- Purpose: Set the non‑negotiables, your project’s guardrails.
# Example prompt:
/constitution Set project law for a web app. Keep the current stack. Library first. Simplicity over abstraction. Integration‑first testing. Enforce auth on all routes. No PII in logs. Encrypt at rest and in transit. Use our design system only. Secrets via env. Allowed regions AU and EU.
The constitution defines the boundaries your project operates within. It captures your non‑negotiables: security rules, coding standards, and architectural principles. Everything that follows must stay within these constraints. Keep the constitution short and stable, link out to heavy policy docs.
What belongs in constitution.md
- Security and compliance: auth, data handling, logging, PII, encryption.
- Coding conventions: naming, folder layout, code style.
- Architecture rules: interfaces first, simplicity, integration-first testing.
- Organisational policies: approved services, geo restrictions, banned libraries, licenses.
/specify
- Purpose: Describe the product goals and outcomes without naming tech.
# Example prompt:
/specify Add a “favorites” feature so users can star recipes in the cooking app. Keep tech‑agnostic. Include user story, acceptance scenarios, requirements (user + recipe + favorite), and success metrics.
Explain the WHAT and WHY, in plain language without naming technology. Put the user story, acceptance criteria, any constraints that matter, dependencies it must respect, and how you will measure success. Then review the draft to tighten scope, remove anything off-mission, and make sure the outcomes are specific and testable before moving on.
Anything unclear will be marked with [NEEDS CLARIFICATION] for review.
What belongs in spec.md
-
User scenarios: primary story, acceptance scenarios, and critical edge cases.
-
Key entities: core data concepts and relationships.
-
Review & acceptance checklist: measurable success criteria, scope bounds, dependencies/assumptions.
/clarify
- Purpose: Resolve the missing or ambiguous details before moving on.
# Example prompt: invoke directly
/clarify
Runs a quick Q&A to surface anything underspecified, ambiguous, or needing clarification. Like answering PM or QA review questions before coding starts. This step reduces rework later by pinning down details early to prevent the Agent going off on a tangent. The prompt helpfully gets the Agent to provide multiple choice suggestions for each clarifying question, to help seed your answer.
e.g. How should the list be ordered? By name or date. How many rows per page?
Notes
- This is fun. Doing quickfire questions and selecting from the multiple choice lets you quickly clarify, and shows you how much context we just assume.
/plan
- Purpose: Define how it will be built. Being explicit with tech stack & frameworks.
# Example prompt:
/plan Use the current stack (React + Node.js + PostgreSQL). Show repo structure, API contracts for add and remove favorite, testing approach, environment setup, and rollback considerations.
Time to define the HOW we want this built. Describe the technology choices and implementation details. Specify the stack, frameworks, and dependencies. Outline the repository layout, contracts, data model, environment setup, and test approach.
If something is missed or you change direction later, simply regenerate the plan from the same spec with updated inputs or new tech choices.
What belongs in plan.md
-
The tech stack: language, frameworks, dependencies, databases, target platforms.
-
Constitution check & structure: how the design satisfies the rules and the concrete repo layout.
-
Design outputs: data-model, API contracts, quickstart guide or setup steps.
-
Testing and tooling: test approach, coverage goals
/tasks
- Purpose: Break the plan into small manageable chunks of work ready for implementation.
# Example prompt
/tasks Create phases and small tasks with acceptance criteria. Start with contracts and tests, then implementation, then polish.
Breaks the plan down into small, verifiable units of work. Each task is meant to be implemented and tested in isolation, ideally small enough to fit in a single commit. Tasks are grouped into phases such as create tests first, verify tests fail, implement, then polish.
What belongs in tasks.md
- Implementation tasks: as small atomic pieces of work that can be done in a commit.
- Phases & order: e.g. setup → tests first (must fail) → implementation → integration → polish.
- Validation gates: checklist to confirm before Agent progresses.
- Note: Don’t check this in. Throw it away. Regenerate if needed.
/analyze
- Purpose: Consistency and compliance check across all the documents before coding.
# Example prompt: invoke directly, it is a validator
/analyze
Checks for any conflicting information or inconsistencies across the documents. It cross‑checks the spec, plan, and tasks against the constitution, flagging conflicts and ambiguities by severity so you know what to act on first. It stays neutral about technology and focuses on your rules and internal consistency. Especially good at spotting naming drift between specs and tasks that would slow code review.
Notes
- Think of it as a pre‑flight check.
- When teams are involved, assign each unresolved ambiguity to an owner.
- Re‑run it after big spec edits, plan changes, or updates to included design docs.
/implement
- Purpose: Generate code one task at a time, with human oversight.
# Example prompt
/implement Run tasks in order. Pause after each for review. If a task fails checks, revise the plan and continue.
Steps through the tasks, generating code according to the plan and constitution. Each output is reviewed before moving forward. Code is delivered task by task, with the Agent doing it iteratively not as one big dump.
Notes
- Follow task order and stop if a task doesn’t meet its acceptance criteria.
- Keep the constitution in view. Don’t introduce new dependencies or patterns that the plan didn’t allow.
- Re‑run analyze after large refactors or when generated code drifts from the plan.
Experimenting with tech stacks
The separation between the What & Why (spec.md) and the How (plan.md) allows you to run quick throwaway spikes to experiment with different tech stacks and implementations.
Allows you to experiment implementing a console app in Dotnet, and then Golang.
- Start from the same spec. Create alternate implementation plans with different stacks, libraries, or deployment targets.
- Do not worry about completeness; plans are cheap to regenerate from the same spec with new inputs.
- If a spike uncovers something that changes your understanding, write that back into the spec or constitution.
Handling Spec Kit on Long‑term projects
Most of this comes down to how you want to maintain context over time. Pick a strategy and be consistent.
Living specs
-
When to use: Fast-moving teams; likely re-implementation on new stacks.
-
Keep the spec up to date so it always matches the current state and learnings.
-
Great for cutting edge work where platforms, frameworks, libraries are still in flux. Can reimplement spec on a new tech stack at any time.
-
Cons: needs discipline. Reviewers must police drift.
Rolling specs (ADR-style)
-
When to use: Long-lived systems wanting the history of changes.
-
Treat specs like ADRs. Write a new spec that supersedes or extends the old one.
-
Clean history, strong traceability, easier audits.
-
Cons: you must “play back” a sequence of specs to see the final state.
Context snapshots
- When to use: Working with different agents. Short lived specs to make changes.
- Maintain a living summary set e.g.
docs/context.md,docs/architecture.md. - For a change, write a feature spec and plan, implement, delete.
- Fold only durable learnings into the summary set.
- A strategy to use Spec Kit to direct single changes, while keeping repo clean with standard agent context files.
Quick guide
-
Will we want to regenerate the app later from specs?
- Yes → Living specs.
-
Do we need strong traceability over time?
- Yes → Rolling specs.
-
Do we mainly need a small, current context for agents?
- Yes → Context snapshots.
Community feedback
Early feedback and discussions I’ve seen around ways of using, friction points, and requested features.
Forced branching strategy
My biggest friction point. Calling /specify creates a new branch for your feature. I prefer being in control of my branches.
Roadmap plans: Adding flags to opt out of auto-branching or set branch name patterns.
Forced TDD workflow
Prompts & templates written with a heavy emphasis on TDD. Impractical for many types of work (doc updates, styling, etc).
Roadmap plans: Acting on the feedback, are creating a set of prompts without the TDD.
Monorepo
Spec Kit assumes a monorepo, with .specify in the project root. But different projects within repo may want different constitution.md files (backend, API, front end, etc).
Roadmap plans: Looking to allow .specify folders throughout the repo for more specific context.
Org level Constitution & security docs
Relevant to all coding Agents. Documenting your organisation’s standards (security, etc) will enhance the context of any Agent. The constitution.md file can then link to those files.
Tip: Start capturing your standards around security, compliance, data handling, logging, PII, encryption.
Closing
I’m enjoying the work flow of Spec Kit and I’ll keep using it on real features. I’ll try the long-term context strategies, then share back what works.
This space is actively developing new strategies weekly. If you’ve found patterns that help, I want to learn from them too.
Quick takeaways
- Keep
constitution.mdshort. Link to org standards. - Treat
spec.mdas the source of truth. Update it while working on the feature. - Regenerate
plan.mdwhen tech choices change. - Delete
tasks.mdbefore merging.
Demos
For my demos I created this example for a “bubble tea ordering system”.
Constitution
Set things up for a shop that has bad connectivity, they just want to something standalone.
/constitution for a bubble tea shop.
Context: In-shop use; the system must work without internet access and produce deterministic results.
Constraints: Local-only data/config; no external APIs/services; no telemetry; minimal dependencies; fast startup; small footprint.
Ops: Friendly, actionable errors; simple logs to local disk; clear README quickstart.
Specify
Let it infer the model from the catalog
/specify a "Bubble Tea ordering system"
User can select one of two flows:
1) Signatures: user picks a predefined drink (from catalog.yml) and sees the final total (AUD price, sugar grams, allergen badges).
2) Build Your Own: step through Size → Base → Milk → Sweetness → Ice → Toppings; show the same final total.
Requirements:
- Import options from ./data/catalog.yml (sizes, bases, milks, sweetness, ice, toppings, signatures).
- Pricing = size.base_price + milk.price_delta + Σ(topping.price) + sweetness.price_delta; round total to nearest $0.05.
- Sugar(g) = size.sugar_g_base × sweetness.sugar_mult.
- Allergen badges derived from milk/toppings (dairy, egg).
Data model:
- Infer entities/fields from catalog.yml
Plan
Showing you can implement the same spec in two completely different technologies and user interfaces
Dotnet 9 CLI
Creating it with a terminal UI! Quicker to generate, and usually pretty consistent good results.
/plan we are building a .NET 9 interactive CLI using Spectre.Console; offline-only.
Read ./data/catalog.yml with YamlDotNet.
Keep dependencies minimal; no external APIs/telemetry.
Vue + Vite
Completely client side web app
/plan Client-only web app with Vue 3 + Vite; no backend.
Convert data/catalog.yml → public/catalog.json at build; fetch once on load.
Render Signatures & BYO; compute totals in a small utils module; print-friendly receipt.
No external APIs/telemetry; fast startup; vibrant pastel UI.
UI: vibrant pastel cards, big tile buttons, emoji badges; print-friendly receipt. Minimal local CSS.
Flask + HTMX
Need to provide a bit more of the how, as there is more UI to build and a frontent/backend. This one takes a much agent coding time to complete
/plan Python web app with Flask + Jinja + HTMX (offline-only).
No server session/state; No DB/auth/external APIs; deterministic outputs.
Load ./data/catalog.yml at startup (PyYAML).
Server-render full pages with Jinja; use small Jinja partials (e.g., _summary.html, _totals.html) for fragments.
/calc recomputes totals from catalog.yml each time and returns a fragment to swap in.
HTMX requests to include the FULL selection (size, base, milk, sweetness, ice, toppings[]) via form fields (hx-include="form").
UI: vibrant pastel cards, big tile buttons, emoji badges; print-friendly receipt. Minimal local CSS.
catalog.yml
I place this file at data/catalog.yml to drive the creation.
schema_version: "bubble-tea-catalog/v1"
currency: "AUD"
defaults:
milk: none
ice: normal
sweetness_pct: 100
limits:
max_toppings: 3
allow_duplicate_toppings: false
sizes:
- { key: S, display: "Small 360ml", base_price: 5.0, sugar_g_base: 30 }
- { key: M, display: "Medium 500ml", base_price: 6.0, sugar_g_base: 40 }
- { key: L, display: "Large 700ml", base_price: 7.0, sugar_g_base: 55 }
bases:
- { key: black, display: "Black Tea" }
- { key: oolong, display: "Oolong Tea" }
- { key: jasmine, display: "Jasmine Green Tea" }
milks:
- { key: none, display: "No Milk", dairy: false, price_delta: 0.0 }
- { key: fresh, display: "Fresh Milk", dairy: true, price_delta: 0.8 }
- { key: oat, display: "Oat Milk", dairy: false, price_delta: 1.0 }
- { key: creamer, display: "Non-dairy Creamer", dairy: false, price_delta: 0.6 }
sweetness:
- { pct: 0, label: "0%", sugar_mult: 0.00, price_delta: 0.0 }
- { pct: 25, label: "25%", sugar_mult: 0.25, price_delta: 0.0 }
- { pct: 50, label: "50%", sugar_mult: 0.50, price_delta: 0.0 }
- { pct: 75, label: "75%", sugar_mult: 0.75, price_delta: 0.0 }
- { pct: 100, label: "100%", sugar_mult: 1.00, price_delta: 0.0 }
- { pct: 125, label: "125%", sugar_mult: 1.25, price_delta: 0.2 }
ice:
- { key: none, display: "No ice" }
- { key: less, display: "Less ice" }
- { key: normal, display: "Normal ice" }
toppings:
- { key: pearls, display: "Tapioca Pearls", price: 0.8, allergens: [] }
- { key: grass, display: "Grass Jelly", price: 0.7, allergens: [] }
- { key: cheesefoam, display: "Cheese Foam", price: 1.2, allergens: [dairy] }
- { key: pudding, display: "Egg Pudding", price: 1.0, allergens: [egg] }
- { key: redbean, display: "Red Bean", price: 0.8, allergens: [] }
signatures:
- key: brown-sugar-milk
name: "Brown Sugar Milk Tea"
preset: { size: M, base: black, milk: fresh, sweetness_pct: 100, ice: normal, toppings: [pearls] }
price_override: 8.8
- key: jasmine-lychee-jelly
name: "Jasmine Lychee Jelly Tea"
preset: { size: L, base: jasmine, milk: none, sweetness_pct: 50, ice: less, toppings: [grass] }