Why-What-How: A structure for project knowledge
❗ DRAFT: This is an early draft that I am sharing. Needs further refinement and editing ❗
In my previous post on capturing project knowledge to help coding agents, I wrote about the practical first step, getting your implicit standards and conventions into markdown so agents stop guessing. This is a great start on the journey to get more consistent results, but as you build up more and more the focus shifts. Where you put it and how you organise it starts to matter just as much as whether you capture it at all.
This post is about a structure I have built up over time called Why-What-How, that organises project knowledge into layers that humans can navigate and agents can progressively load.
The problems I kept seeing
Even on teams that were writing things down, the same problems kept showing up.
Information was scattered everywhere. Key decisions about the architecture would appear in research notes, inside SDD (Spec Driven Development) specs, in ADRs (Architecture Decision Records), or buried in pull request descriptions. When an agent needed to understand how the system was designed, it had to search through everything — and it would still miss things. There was a lot of repeated information, and worse, outdated information that contradicted the current state.
Everything sat at the same level. There was no layering or hierarchy. The business problem statement, a component-level flow diagram, a coding convention, and a technology choice all lived side by side in a flat folder. Developers were trying to tackle everything at the same level of abstraction instead of breaking it into layers. When you read a spec, it might jump from “the customer needs to place an order” to “we use a Redis cache for session state” in the same paragraph.
The approaches were developer-centric. Most of the spec-driven and planning workflows I was seeing were written by developers, for developers. They worked well for scoping code changes but the solutions they produced kept drifting bottom-up — starting from technical details and working backward to justify them. The business problem that originally motivated the work would get buried or forgotten entirely. And other roles on the team — programme managers doing stakeholder discovery, data scientists running evaluations, designers doing user research — had no clear place in the structure. Their work would live in separate documents that did not connect back to the shared knowledge.
Diagrams did not validate against anything. I kept seeing teams generate Mermaid diagrams of parts of the system and commit them. Then someone else would generate another diagram, and the names would not match, the flows would differ, and sometimes they would show relationships that did not exist. Each diagram was an independent drawing with no connection to any other diagram. There was no way to know which one was correct when they contradicted each other. Mermaid is a great rendering format, but it is not a modelling tool — it does not validate relationships or enforce consistency across views. This is something I want to explore more in a future post, but the short version is: I started using C4 model DSL as a structural source of truth instead, where the model validates that elements and relationships actually exist before you can render them.
The shift that helped
I tried a few different approaches to organising this knowledge before landing on something that worked. The key realisation was that I needed to separate the layers of abstraction and make them explicit.
The business intent needed to be self-contained. When I pulled out the “why are we building this?” into its own area — the problem context, the people we are serving, the journeys they go through, the scenarios that describe expected behaviour — it became a clean black-box definition. It described what the system must do from the outside without saying anything about how. That meant the business intent stayed stable even when the architecture changed underneath. And it meant anyone on the team — not just developers — could contribute to it and understand it.
The solution structure needed its own space. What we are concretely building — the system boundary, the applications, how they decompose into components, how interactions flow between them — is the white-box implementation. Pulling this into a separate area made it much easier to reason about structure without getting tangled in business framing or coding conventions.
Cross-cutting constraints needed a home. Engineering conventions, observability standards, security patterns, testing approaches — these apply across everything but they are not about the business problem or the solution structure. They needed their own area.
Decisions needed to be preserved. Why did we choose this technology? What alternatives did we reject? What trade-offs did we accept? Without a place for this, teams would re-litigate the same decisions because nobody could find the original reasoning.
The four areas
That is the framework. Four areas, each with a clear purpose.
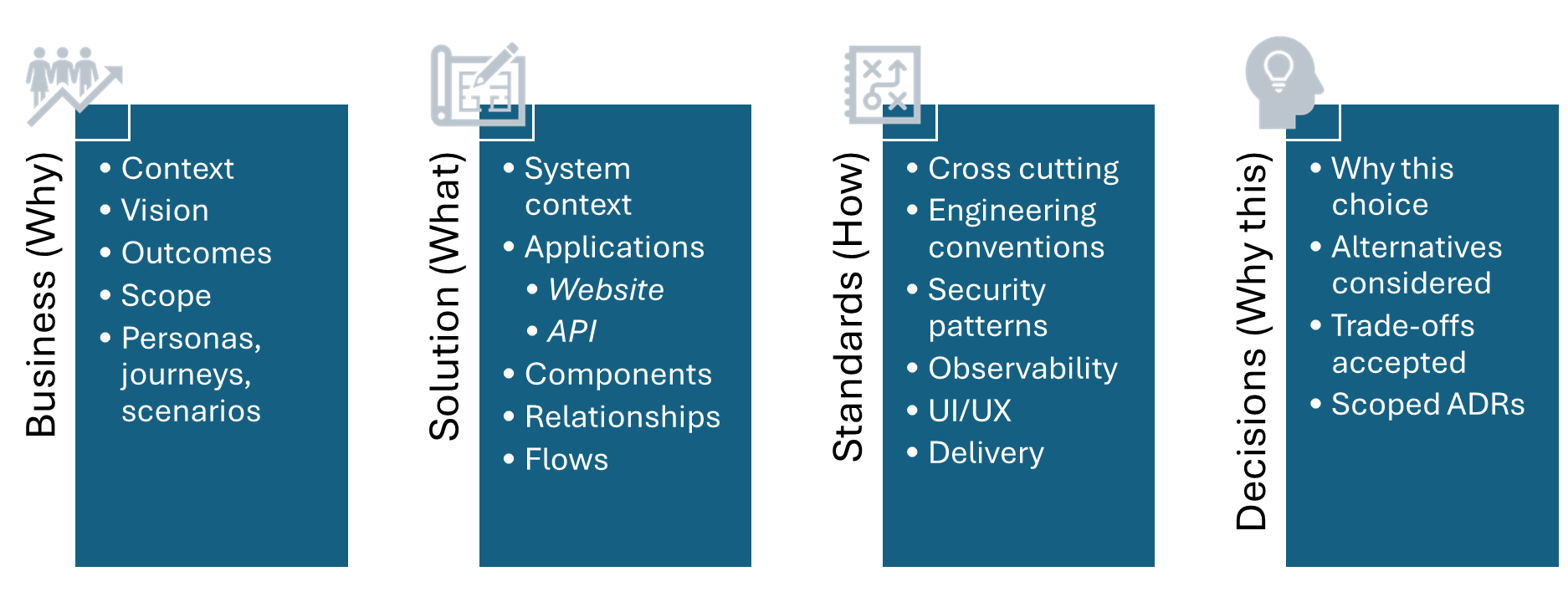
| Area | Frame | What it answers |
|---|---|---|
| Business | Why | Why does this exist? Who are we serving? What outcomes matter? |
| Solution | What | What are we building? How does it decompose? What owns what? |
| Standards | How | How do we build consistently? What conventions apply? |
| Decisions | Why This | Why did we choose this approach? What did we reject? |
When you are writing something and are not sure where it belongs, the decision tree is simple:
- Is it about intent or expected behaviour? → Business
- Is it about structure or how parts interact? → Solution
- Is it about how we build consistently? → Standards
- Is it about why we made a choice? → Decisions
If you cannot answer any of those, it probably does not belong in the canonical knowledge at all — it might be a scratch pad or working document that has not been distilled yet.
Validation at every layer
One of the things I have noticed as teams adopt agentic workflows is that we are learning where agents need deterministic guardrails. Most of the focus so far has been on TDD (Test Driven Development) — write tests, let the agent implement, check if the tests pass. That catches implementation bugs. But there are two other classes of error that TDD does not catch.
Are we building the right thing? BDD (Behaviour Driven Development) tests validate that the scenarios defined in the business layer actually hold. They catch intent errors — “the code works, but it does not do what the business needed.”
Do the pieces fit together? The C4 model validates the structural integrity of the solution. If a flow references an application or relationship that does not exist in the model, the DSL catches it. It catches structural errors — “the components work individually, but the overall system does not connect the way we described.”
Together with TDD at the implementation layer, this gives you validation at every level: business intent, solution structure, and code correctness. Without all three, agents can produce code that runs but does not match the business need, or structure that compiles but does not align with the agreed architecture.
It works with however you already work
This is probably the most important thing to say: Why-What-How is not a new process. It is a structure that existing processes feed into.
If you are using SDD or RPI (Research-Plan-Implement) cycles — keep doing that. Your specs and plans can live in a specs/ folder as they always have. The difference is that they can now reference the shared knowledge in docs/ for the business context, solution architecture, and standards. That means each spec carries less repeated background, gets more consistency, and stays aligned with what the team has already agreed.
If you are doing Design Thinking — keep doing your workshops, your user research, your persona development. When those activities produce conclusions that matter, distil them into the Business area. Your personas, journeys, and scenarios become first-class documents that the whole team (and agents) can reference.
If you are starting a new project and having initial meetings with a product owner — start capturing that in Business. The problem context, the vision, the expected outcomes. As you learn where the system will be deployed and which existing systems it will interact with, start capturing that in the Solution context. Then the combination of business understanding and system context can help inform the decomposition — what applications you need, what components they contain, and what flows connect them.
The key principle: your scratch pads stay wherever your workflow puts them. When those activities produce conclusions that matter, distil them into the right area. The canonical knowledge stays in docs/. Research notes, brainstorming artifacts, SDD specs, and working documents stay outside. They feed in; they do not need to live inside.
As teams make decisions that change the design or the standards, they capture those in docs/. The next spec, the next agent session, the next new team member — they all start from high-signal, up-to-date canonical knowledge instead of searching through everything.
Seeing it in practice: bubble tea kiosk
To make this concrete, I created a reference example: a bubble tea ordering kiosk for a fictional shop called Compile & Sip. It is a documentation-only repository — no source code, just the docs layer — so you can see the framework in practice without distraction. The full repo is at why-what-how-bubbletea-kiosk-example.
Here is one thread through the framework, following a single user action end-to-end.
Business layer — the why. The problem is real: peak-hour queues cause 20–30% of potential customers to walk away, and verbal order relay leads to wrong milk types, forgotten toppings, and wasted drinks. One of the personas is Alex, a regular customer who values order accuracy and speed. Alex’s journey — approaching the kiosk, browsing the menu, customising a drink, paying, and picking up the order — is captured as a narrative. From that journey, specific testable scenarios are derived: “order is accepted with valid customisations”, “payment is processed successfully”, and so on. Each scenario describes what must happen from the outside — no mention of APIs, databases, or services.
Solution layer — the what. Knowing the business need, the solution decomposes into three applications: a customer-facing kiosk UI, a central order API, and a kitchen display. The system context captures the boundary — what is inside the system and what is external (the payment gateway). Each application has its own folder with a context document explaining its responsibilities. Flows describe how an interaction unfolds across applications — for example, the “submit order” flow traces from the kiosk through the order API and back. These flows are defined in the C4 model, which means the applications and relationships they reference must actually exist in the structural model.
The folder structure reflects this layering:
docs/
├── business/ # WHY — intent, people, behaviour
│ ├── business-context.md
│ ├── vision.md
│ ├── personas/ # Alex (customer), Jamie (kitchen staff)
│ ├── journeys/ # Customer places order, Staff prepares order
│ └── scenarios/ # 5 testable scenarios
│
├── solution/ # WHAT — structure, decomposition
│ ├── solution-context.md # System boundary and external systems
│ ├── applications/ # Kiosk UI, Order API, Kitchen Display
│ └── c4-model/ # Structural source of truth
│
├── standards/ # HOW — conventions and constraints
│
└── decisions/ # WHY THIS — ADRs with scope
├── ADR-0001-solution-dotnet-platform.md
├── ADR-0002-application-order-api-in-memory-storage.md
└── ADR-0003-solution-rest-http-polling.md
Notice that the directory structure matches the abstraction layers. Business is self-contained — you can read it without knowing anything about the solution. Solution references business scenarios but never the other way around. Decisions are scoped by area so an agent working on a specific application only loads the decisions relevant to that application.
Progressive context loading
This layering also solves the context overload problem.
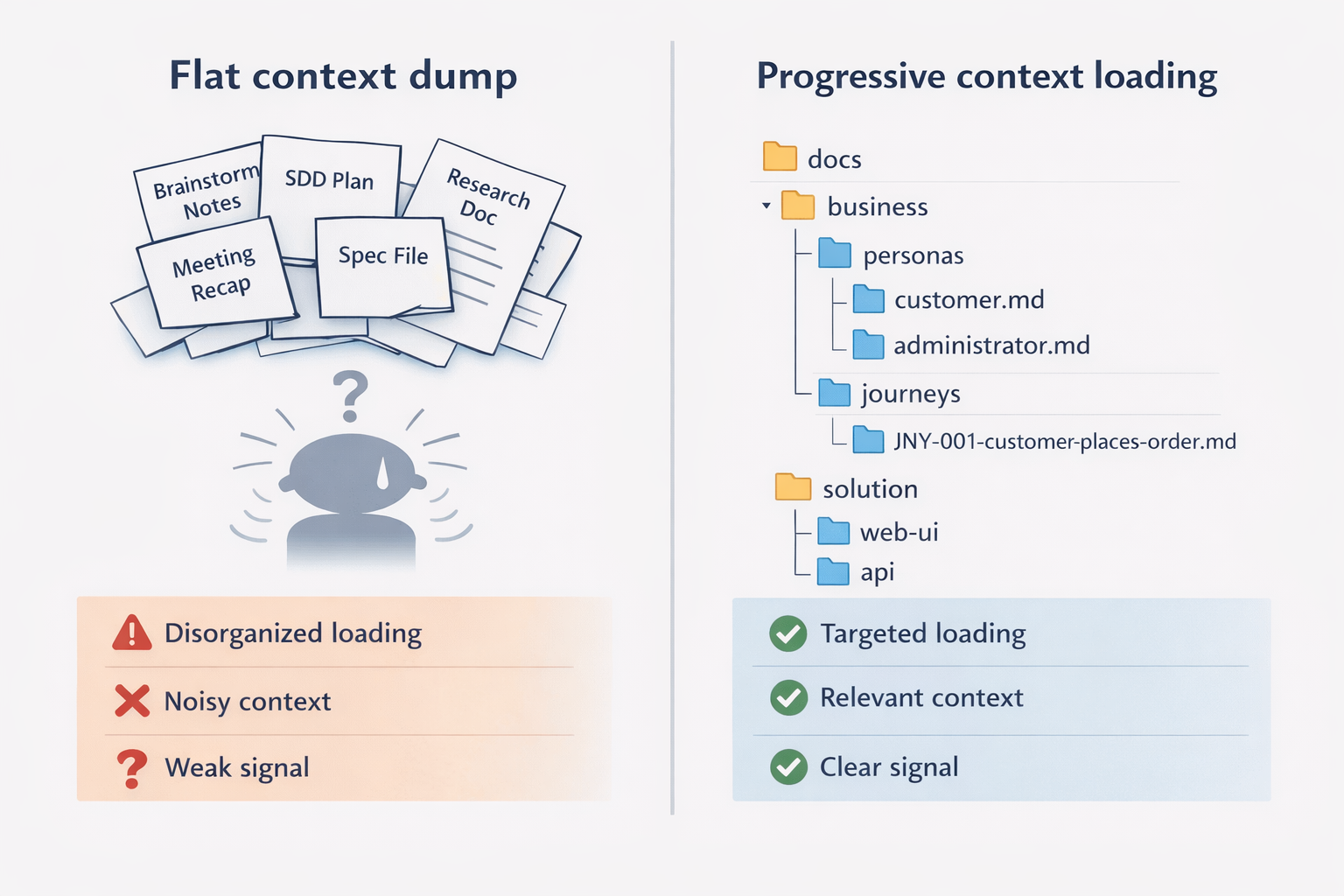
When every markdown file sits at the same level, agents treat them all as equally important. A vision statement, a brainstorming scratch pad, an old spec plan, and half-finished research findings all look the same. The agent loads everything and the signal drowns in noise.
With the layered structure, directory depth matches abstraction depth. An agent working on business framing loads the business/ folder — it does not need solution details. An agent working on the order API loads solution/applications/order-api/ — it does not need to read every persona and journey. An agent helping with system-level architecture loads solution/solution-context.md — it does not need application-level flows.
This is not just about agents. New team members orient faster too. You read the business context to understand the problem, skim the solution context to understand the shape, and dive into the specific application you are working on.
Getting started
You do not need all of this on day one. The framework includes a bootstrap playbook with phases:
- Foundation — four files:
business-context.md,vision.md,outcomes.md,scope.md. Just enough to explain what the project is, who it serves, and what it will do. - Who and Why — at least one persona, one journey, one scenario. Enough to ground the work in real user behaviour.
- Solution Structure — system context, applications identified, first ADR. Enough to see the structural shape.
- Depth — flows, components, BDD tests, standards. Add these as the project needs them.
Start with Phase 1. Copy the docs/ folder from the why-what-how framework repository into your project. It contains the guidance files that define the model, conventions, folder structure, and bootstrap playbook. Populate the four Phase 1 files with real content about your project. Build depth incrementally from there.
If you want to see what a fully populated example looks like, explore the bubble tea kiosk example.
Closing
The core idea is not complicated. Separate the layers of abstraction. Give each one a canonical home. Stop making agents and humans search through everything to find the signal.
Capture the business intent in one place. Capture the solution structure in another. Keep your standards and decisions alongside them. Let your existing workflows feed into the structure, and let the structure give back high-signal, consistent, up-to-date context for everything that comes next.
- Framework and guidance files: why-what-how
- Worked example: why-what-how-bubbletea-kiosk-example